이전 글에서 Shared Memory의 용도에 대해 이야기 하면서, 만약 Global Memory에 데이터가 정렬되어 있지 않다면 Shared Memory를 사용할 수 있다고 했었습니다. 해당 내용을 생각해 보면 정렬되지 않은 Global Memory에 대한 접근은 성능적으로 악영향을 끼칠 수 있겠다는 것을 짐작해볼 수 있습니다. 따라서 오늘은 왜 이러한 성능 하락이 일어나는지 이해해 보고 어떠한 상황을 Memory Coalescing이라 할 수 있는지 알아 보겠습니다.

CUDA에서 각각의 Thread는 흐름 제어를 할 수 없고, SM이 Thread들을 32개로 묶어서 Warp 형태로 흐름제어를 하게됩니다. 이에 따라 Global 메모리에 접근할때도 32개의 Thread가 동시에 메모리에 접근하게 되는데, 이때 Cache Line내에 연속된 메모리 공간에 접근하는 것을 Memory Coalescing(또는 Coalesced Memory Access)이라고 합니다.
Memory Coalescing을 위한 요구 사항은 GPU의 compute capability에 따라 다릅니다.
일반적으로 다루게 되는 Compute Capability 6.0 이상에서는 Warp내 모든 Thread들의 동시 접근은 몇 개의 Transection으로 통합될 수 있습니다. 즉 Warp내 모든 Thread들의 접근이 32byte내에서 이뤄진다고 하면 하나의 Transection으로 접근이 가능하고, 그렇지 못하면 여러 번의 Transection이 일어날 수 있습니다.
참고로, Compute Capability 6.0 이상에서는 L1-Caching이 기본입니다. 그리고 메모리 접근 단위는 L1 Cache나 Global Memory 할거 없이 32-byte입니다.
다음 아래 예제는 4-byte 단위(e.g., float)로 Warp내 Thread들이 인접한 메모리에 정렬된 접근을 가정했습니다. 따라서 4byte x 32 = 128byte이므로 96에서 224까지 접근하는것을 확인할 수 있습니다. 이 경우네는 4번의 통합된 Transection으로 메모리에 접근할 수 있습니다. 또한 만약 몇몇 Thread들이 같은 word에 접근하거나, 몇몇 Thread가 access를 하지 않아서, 32-byte Segment에서 하나 word(4-byte)에 대해서만 요청이 있다고 하더라도 Segment 전체가 fetch 됩니다.
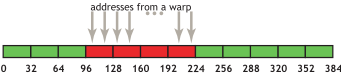
아래는 위와 달리 정렬된 접근이 아니라서 하나의 Transection을 더 사용하게 되었습니다. 그렇지만, 현실에서는 CUDA Runtime API를 통해 메모리 할당을 하는 경우 최소 256bytes로 정렬되도록 보장되기 때문에, Block의 크기를 Warp의 배수가 되게 지정한다면 정렬된 메모리 액세스를 하기 훨씬 쉬워집니다.

아래는 정렬되지 않은 접근(misaligned accesses)이 어떤 효과를 미치는지 잘 보여주는 Nividia의 예제입니다.
offset을 0부터 32까지 변경해보며 테스트를 진행하였고, 각 offset별 Bandwidth를 확인함으로써 성능을 평가해 볼 수 있습니다.
__global__ void offsetCopy(float *odata, float* idata, int offset)
{
int xid = blockIdx.x * blockDim.x + threadIdx.x + offset;
odata[xid] = idata[xid];
}아래의 그래프를 통해 결과를 확인해 보면, offset이 8의 배수였을 경우 4번의 32byte - Transection이 수행이 되어 대략 790 GB/s의 성능을 보여줍니다. 그리고 우리는 그 외의 offset에서는 대략 5분에 4정도의 메모리 처리량을 보여줄거라고 기대할 수 있지만 생각보다 높은 성능(10분의 9정도의 성능)을 보여주고 있음을 알 수 있습니다. 그 이유는 인접한 Warp는 이웃이 가져온 Cache를 재사용하기 때문에 그렇습니다. 즉 Cache가 misaligned sequential accesses에 대한 영향을 줄어줄 수 있습니다.

이어서 아래의 예제는 Strided Access입니다. 이전에는 모든 Thread가 인접한 데이터에 접근하였지만 지금은 일정한 간격을 가지고 접근하는 경우입니다.
__global__ void strideCopy(float *odata, float* idata, int stride)
{
int xid = (blockIdx.x*blockDim.x + threadIdx.x)*stride;
odata[xid] = idata[xid];
}예를들어 stride값이 2인 경우 아래와 같은 이미지로 표현해볼 수 있습니다.
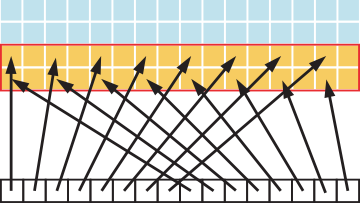
이 경우에도 이전과 마찬가지로 그래프를 통해 성능을 파악해 보면 엄청난 성능 하락을 확인할 수 있습니다.

2-Stride의 경우에 Transection내 절반이 낭비되어 대역폭을 잡아먹고 있기 때문에 50%의 성능을 보여주고 있습니다. 따라서 개발하는 과정에서 이러한 접근은 가능한 피해야 합니다. 그리고 이러한 접근이 꼭 필요하다고 하면 이전에 이야기 했던 Shared Memory을 사용하여 비효율성을 해결해 볼 수 있습니다.
Reference
https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/#coalesced-access-to-global-memory
CUDA C++ Best Practices Guide
CUDA devices use several memory spaces, which have different characteristics that reflect their distinct usages in CUDA applications. These memory spaces include global, local, shared, texture, and registers, as shown in Figure 2. Of these different memory
docs.nvidia.com
'병렬 프로그래밍 > CUDA' 카테고리의 다른 글
| [실습] CUDA의 Cooperative Groups (0) | 2023.03.05 |
|---|---|
| [실습] Nvidia BoxFilter 예제 분석 (0) | 2023.02.18 |
| [기본] CUDA내 다양한 Memory들 (0) | 2023.02.11 |
| [기본] Shared Memory에 대해 (0) | 2023.02.04 |
| [기본] Thread Layout 설계 시 고려되어야 할 점들 (0) | 2023.01.31 |



