CUDA에서 Shard Memory는 굉장히 중요하면서도 사용하기 어렵습니다. 왜냐하면 잘못된 방식으로 코드를 작성하여 Shared Memory에 비효율적으로 Access하거나 너무 많이 사용할 경우, 사용하기 전에 비해 오히려 성능이 하락하는 경우를 심심치 않게 볼 수 있습니다. 따라서 Shared Memory를 올바르게 사용하기 위해 Shard Memory가 무엇이고, 어떻게 사용해야 하는지에 대해서 이야기 해보겠습니다.
Shared Memory는 on-chip메모리로서 Global, Local Memory에 비해서 높은 Band-Witdh와 낮은 Latency를 보여줍니다. (단, Bank Conflict가 없다는 전제하에) 따라서 주로 Global Memory에 Access하는 횟수를 줄이기 위해 Cache(User-Managed Cache)로 사용되거나 Thread간 통신하는 용도로 이용됩니다. 또한 Shared Memory를 사용하지 않는다고 하면 L1 Cache(Hardware-Managed Cache)로 설정하여 활용할 수도 있습니다. 밑에서 코드를 보며 추가적인 설명을 해보겠습니다.
아래의 예제는 Shared Memory를 Thread간 통신하는 용도도로 사용하는 대표적인 예입니다.
Thread 개수만큼 Shrared Memory를 정의하고, 각각의 Thread는 Shared Memory에 접근하여 값을 읽고, 또 계산을 마친 후 저장하고 있습니다. 이 과정에서 Shared Memory는 계산 상태를 저장하고 있고, 그 값을 각각의 Thread가 공유하고 있습니다. 또한 이 과정에서 해당 함수는 Block 단위로 실행되기 때문에 값을 쓸때 __syncthreads()를 통해 동기화를 수행하고 있습니다. (반대로 Warp단위로 실행되는 코드에서는 위와 같이 thread간 sync를 맞춰주지 않아도 됩니다.)
Shared Memory를 선언하는 부분이 Kenal함수에 있어서 각 Thread마다 선언한 만큼 Shared Memory를 사용한다고 생각할 수 있지만, 그렇지 않고 Shared Memory를 초기화하는 코드는 딱 한번만 실행됩니다.
__device__ float reduceSum(float* temp, float val) {
int curr = threadIdx.x;
for (int i = blockDim.x / 2; i > 0; i /= 2) {
temp[curr] = val;
__syncthreads();
if (curr < i) {
val += temp[curr + i];
}
__syncthreads();
}
return val;
}
__global__ void dot(float* a, float* b, float* result, size_t size) {
float sum = threadMultiSum(a, b, size);
__shared__ float temp[THREADS];
float blockSum = reduceSum(temp, sum);
if (threadIdx.x == 0) {
atomicAdd(result, blockSum);
}
}다음은 Global Memory에 접근을 최소화 하기 위해 Cache로 Shared Memory를 사용하는 예입니다.
아래의 이미지를 보시면, Shared Memory를 Block Dimension크기(THREADS x THREADS)만큼 선언한 후, Global Memory에서 값을 읽어서 Shared Memory로 저장합니다. 그 이후에 반복되는 계산에서 Shared Memory를 사용하여 계산을 수행하고 있습니다.

__global__ void mulMatrixWithSharedMemory(TARGET_TYPE* c, const TARGET_TYPE* a, const TARGET_TYPE* b, const unsigned int N)
{
__shared__ TARGET_TYPE tempA[THREADS][THREADS];
__shared__ TARGET_TYPE tempB[THREADS][THREADS];
int col = blockDim.x * blockIdx.x + threadIdx.x;
int row = blockDim.y * blockIdx.y + threadIdx.y;
int localCol = threadIdx.x;
int localRow = threadIdx.y;
TARGET_TYPE sum = 0;
for (unsigned int bid = 0; bid < ceil((float)N / blockDim.x); ++bid) {
if (row < N && bid * blockDim.x + localCol < N) {
tempA[localRow][localCol] = a[N * row + (bid * blockDim.x + localCol)];
}
else {
tempA[localRow][localCol] = 0;
}
if (col < N && bid * blockDim.y + localRow < N) {
tempB[localRow][localCol] = b[N * (bid * blockDim.y + localRow) + col];
}
else {
tempB[localRow][localCol] = 0;
}
__syncthreads();
for (unsigned int idx = 0; idx < blockDim.x; ++idx) {
sum += (tempA[localRow][idx] * tempB[idx][localCol]);
}
__syncthreads();
}
if (row >= N || col >= N)
return;
c[row * N + col] += sum;
}전체 코드는 이 링크에서 확인해 보실 수 있습니다.
Shared Memory는 Global Memory에서 Memory Coalescing(Coalesced Memory Access)으로 데이터를 로드 및 저장한 다음 공유 메모리에서 다시 정렬하여 통합되지 않은 메모리 액세스를 방지하는 데 사용할 수도 있습니다. 이 경우 이 다음에 이야기할 Bank Conflict를 제외하고, Shared Memory에서는 Warp에 의한 비순차적 또는 정렬되지 않은 액세스에 대한 페널티가 없습니다.
이제까지 Shared Memory를 사용하는 상황에 대해서 이야기를 해보았습니다. 그렇다면 이어서 Shared Memory를 사용하는데 있어서 주의해야 할 부분에 대해 이야기 해보겠습니다.
가장 먼저 Shared Memory를 얼마나 사용하는지에 대해서 고민을 해야 합니다. 이전에 제가 올린 글에서 Active Block에 대해서 설명을 드렸습니다. Active Block은 모든 Warp들이 Register를 확보하고, Shared Memory도 할당받은 상태를 말한다고 이야기 했습니다. 그리고 이 Activie Block의 상태가 되어야 SM에서 Active Block끼리 Concurrently 동작할 수 있습니다. 따라서 Shared Memory를 너무 많이 할당하는 경우에는 동시성을 해치고 이는 곧 성능의 하락으로 이어집니다.
그 다음에 조심해야할 문제는 Bank Conflict 입니다. 여기서 이야기 하는 Bank는 CUDA에서 각각의 Thread가 Shared Memory에 접근하기 위한 통로라고 생각하시면 됩니다. 그리고 Bank는 보통 32개(4 bytes의 주소값 단위)로 이루져 있습니다. (Bank의 개수와 주소값 단위는 Compute Capability따라 조금씩 차이가 있습니다.)
문제는 CUDA에서는 Warp단위로 동작을 하기 때문에 Shared Memory에 접근하는 방법에는 3가지가 있을 수 있습니다.
- Parallel access: multiple addresses accessed across multiple banks
- 모든 Thread가 각각의 Bank에 접근할 때, conflict-free인 shared memory 액세스가 수행됩니다.
- 각각의 Thread가 Random하게 다른 Bank에 진입하는 것은 Bank Conflict와 무관합니다.
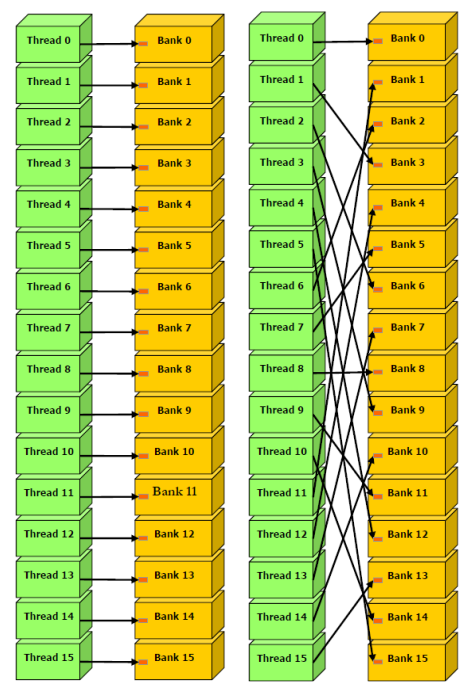
- Serial access: multiple addresses accessed within the same bank
- worst 패턴입니다. 여러 addresses가 동일한 Bank에 속할 때, 그 메모리 요청은 serial로 처리됩니다.
- 만약 warp 내의 모든 스레드가 하나의 Bank에 접근하여 각기 다른 주소값을 요청할 경우 32배 느려집니다.
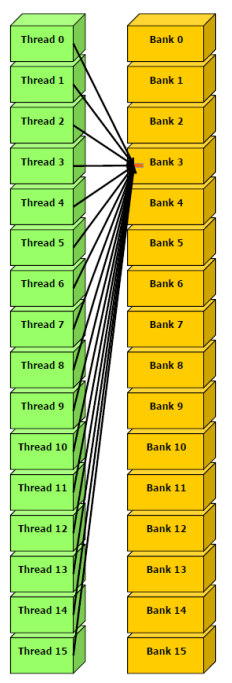
- Broadcast access: 한 warp의 모든 Thread가 하나의 Bank 내의 동일한 주소를 읽습니다.
- 한 번의 memory transaction이 수행되고, 액세스된 word는 모든 스레드로 broadcast 됩니다.
- broadcast access에서 오직 한 번의 memory transaction만이 필요하지만, 아주 적은 양의 bytes만 읽으므로 bandwidth 활용도는 낮습니다.
위와 같은 이유 때문에 메모리 주소가 메모리 Bank에 매핑되는 방식과 메모리 요청을 최적으로 예약하는 방법을 이해하는 것이 중요합니다.
아래 Nvidia 예제 링크에서 Shared Memory를 제대로 사용하는 방법을 행렬곱 예제로 잘 설명해 주고 있습니다.
이 예제를 참고해 보시면 위의 내용들을 더 쉽게 이해하실 수 있습
Best Practices Guide :: CUDA Toolkit Documentation (nvidia.com)
Reference
CUDA C++ Programming Guide (nvidia.com)
CUDA C++ Programming Guide
Texture memory is read from kernels using the device functions described in Texture Functions. The process of reading a texture calling one of these functions is called a texture fetch. Each texture fetch specifies a parameter called a texture object for t
docs.nvidia.com
[MP] Lec 10-2. Maximizing Shared Memory Throughput / CUDA 강의 - YouTube
Shared Memory (1) (tistory.com)
Shared Memory (1)
References Professional CUDA C Programming Contents Shared Memory (SMEM) Shared Memory Banks and Access Mode Configuring the Amount of Shared Memory Synchronization Volatile Qualifier 이번 포스팅에서는 공유 메모리에 대해서 다시 한 번
junstar92.tistory.com
'병렬 프로그래밍 > CUDA' 카테고리의 다른 글
| [실습] CUDA의 Cooperative Groups (0) | 2023.03.05 |
|---|---|
| [실습] Nvidia BoxFilter 예제 분석 (0) | 2023.02.18 |
| [기본] CUDA내 다양한 Memory들 (0) | 2023.02.11 |
| [기본] Memory Coalescing에 이해 (0) | 2023.02.08 |
| [기본] Thread Layout 설계 시 고려되어야 할 점들 (0) | 2023.01.31 |



