[기본] Thread Layout 설계 시 고려되어야 할 점들
CUDA로 프로그래밍을 진행하다 보면 고려해 줘야 할 조건들이 굉장히 많습니다. 특히 일반적으로 CPU에서 동작하는 코드에 비해서 하드웨어 스펙에 의존성이 더 큽니다. 따라서, 이번에는 Thread Layout 설계할 때 성능상 고려해 줘야 하는 것에는 어떤 것들이 있는지 이야기해 보겠습니다.
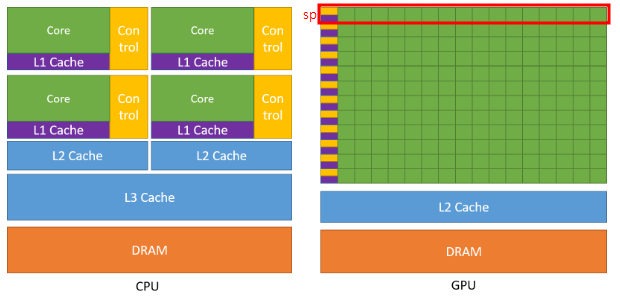
위의 이미지에서 확인할 수 있듯이 GPU는 여러개의 SM(Streaming Multiprocessor)로 구성되어 있고, SM내부에는 또 다수의 Thread(CUDA Core or SP)로 이루어져 있습니다. 그리고 우리는 최대 3차원까지 Grid, Block에 대해서 논리적인 Dimension을 지정해줄 수 있습니다.
(Grid는 GPU를 의미하며 Block의 집합이고, Block은 SP단위에서 실행되며 Thread들의 집합입니다.)
이렇게 논리적으로 설계된 Dimension은 하드웨어에 맵핑되게 되는데, Block들은 GPU가 가지고 있는 SP에 동등하게 분배되게 됩니다. 따라서 Grid Dimension을 설계할 때 최소한, 자신의 GPU가 가지고 있는 SP의 개수보다는 많은 Block을 가지도록 구성해야 노는 SP가 발생하지 않습니다. 또한 SP에서는 블록을 실행할때 Warp(SIMT방식으로 동작하는 32개의 Thread 묶음)단위로 동작하기 때문에 Block의 Dimension을 구성할때, Thread의 구성을 32의 배수로 설정해야 불필요한 동작을 수행하는 Thread들이 없게됩니다. (Warp의 단위보다 적은 .Block Dimension을 구성 하더라도, Warp의 개수만큼의 Thread들이 동작하게 됩니다.) 또한 단지 하드웨의 구성 및 Warp의 개수뿐만 아니라 더 고려해야 할 사항들이 남아 있습니다.
GPU의 각각의 Thread들은 흐름제어를 할 수 없습니다. 따라서 SP가 Warp 단위로 Thread들을 Control하게 됩니다.
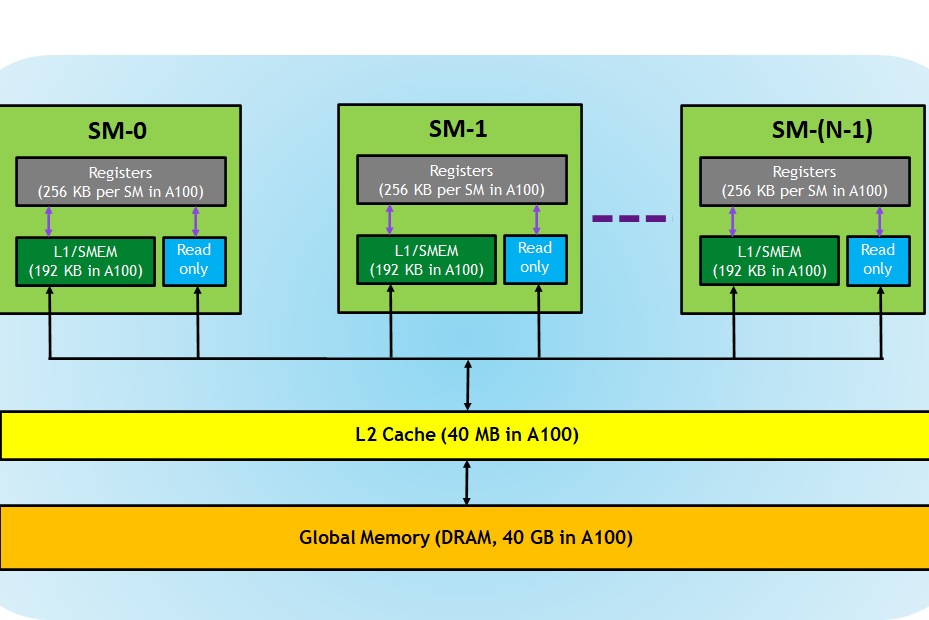
Thread Layout을 설계할때 현재 이 GPU의 메모리 스펙이 어떻게 되는지도 꼼꼼히 따져봐야 합니다. 위 그림에서 확인할 수 있듯이 각각의 SM에는 Registers(Register File)이라는 영역이 존재하고 이 영역은 커널에서 각 Thread가 사용하는 크기 만큼 분할되어 집니다. 그리고 Warp내의 모든 Thread가 Register를 확보한 상태를 Active Warp라고 부르고, 이 상태의 Warp끼리는 이미 Register에 모든 정보가 올라가 있기 때문에 Zero Context Switching이 가능합니다. 즉 Active Warp의 개수가 많다는 이야기는 Warp가 메모리에 접근하는 과정에서 Zero Context Switching을 수행하며 다른 작업을 수행하는 Latency Hiding을 할 수 있다는 의미이므로 성능에 우의를 가지게 됩니다.
이와 비슷한 맥락으로 Block내의 모든 Warp가 Register을 할당 받고, Shared Memory까지 할당 받은 상태를 Active Block이라 합니다. 마찬가지로 이 상태의 Block끼리는 Concurrently 실행됩니다.
이러한 Active Warp에 대한 지표가 Occupancy입니다. Occupancy는 현재 Active Warp수에서 SM에서 최대로 활성화 될 수 있는 Active Warp수(= Active Block의 최대값과 Block당 Warp 수의 곱)로 나눈것을 의미합니다. 이렇게 말로 정리 하면 이해하기 어려우니 예를 들어보면, 어떤 GPU에서 SM당 최대 64개의 Warp를 지원하고, 256(32 x 8)개의 Thread로 구성된 Active Block이 8개가 있다면 현재 theoretical occupancy는 100%라고 할 수 있습니다.
(자기 Device의 최대 Warp수를 확인하고 싶다면, http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities를 참고해주세요.)
다만, Occupancy가 높다고 해서 무조건 더 좋은 성능을 보장하지 않습니다. 따라서 다양한 Thread Layout으로 테스트를 진행하면서 자신의 Kernal에 맞는 구성을 찾아봐야 합니다.
위에서 알 수 있듯이 Block내의 Thread의 수를 늘리게 되면 활성화 될 수 있는 Block의 개수가 줄어들게 됩니다. 반대로 Thead의 개수(Warp의 수)를 줄이게 되면 활성화 되는 Block의 수는 많아 질 수 있지만, Block내의 활성화 될 수 있는 Warp의 수는 줄어들게 됩니다. 또한 이 밖에도 Shared Memory와 Register의 사용량도 고려해 주어야 합니다. 따라서 Thread Layout을 구성하는 것은 생각보다 많이 복잡합니다. 따라서 이를 계산해주는 Tool이 따로 존재하는데요. 바로 NSight Compute입니다.
만약 자신이 CLI 환경이라고 한다면, Nsight Compute CLI :: Nsight Compute Documentation (nvidia.com)를 참고해 보실 수 있고, Windows 환경이라면 아래와 같이 GUI를 통해서 Thread Per Block, Register Per Thread, Shared Memory Per Memory를 바꿔가며 Occupancy를 계산해 볼 수 있습니다.
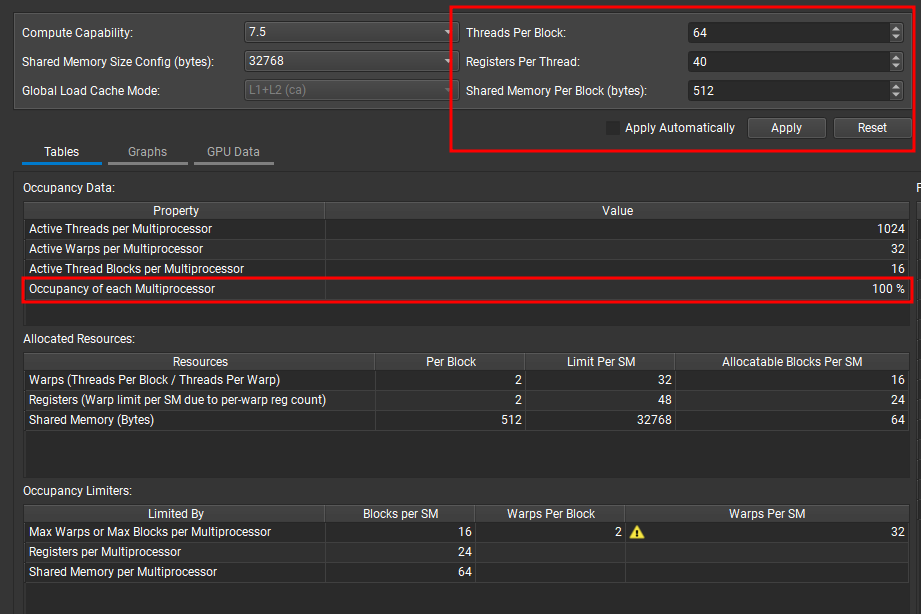
참고
Achieved Occupancy (nvidia.com)
Achieved Occupancy
Shows how varying the block size while holding other parameters constant would affect the theoretical occupancy. The circled point shows the current number of threads per block and the current upper limit of active warps. Note that the number of active war
docs.nvidia.com
[MP] Lec 9. CUDA Memory Model (2/4) - Memory Model & Performance / CUDA 강의 - YouTube