일반적으로 inference 엔진들은 다양한 타입을 입력으로 받고, 또 다양한 device들에서 동작되어야 합니다. 그런데 이 조건들을 충족하게 개발하는게 개인적으로 쉽지 않았습니다. 그래서 기존에 잘 만들어진 라이브러리들을 많이 벤치마크하게 되었고, 오늘은 그 중에서 caffe2에 대해서 이야기 해보려고 합니다.
(단, 코드가 너무 방대하다 보니 제가 잘못 이해한 부분도 있을거라 생각됩니다. 그런 부분들은 댓글을 통해 지적해 주시면 감사하겠습니다.)
caffe는 원래는 University of California, Berkeley에서 개발된 딥 러닝 프레임워크로서 독립적으로 존재했지만, Facebook에서 RNN기능을 지원하면서 caffe2를 발표하였고, 지금은 pytorch에 편입되어 같은 repository에서 관리되고 있습니다.
GitHub - pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration
Tensors and Dynamic neural networks in Python with strong GPU acceleration - GitHub - pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration
github.com
따라서 위에 repository의 root에서 caffe2를 통해서 코드들을 확인해 볼 수 있습니다.
Observable
예를 들어 특정 net에서 어떤 동작(StartObserver)이 시작되면, 이 net에 등록되어 있는 하위의 operator들에 동작을 쉽게 전파될 수 있습니다. 그 반대도 마찬가지 입니다.
예를들어 ProfileOperatorObserver 같은 경우에는 네트워크에서 실행한 operator에 대해서 정보들을 출력하게 하고, TimeOperatorObserver는 소요된 시간을 출력할 수 있습니다. (stop이라는 인터페이스)
코드를 확인하는 과정에서 가장 재밌었던건, cache(Observer*)를 둬서 0번 인덱스의 객체를 따로 관리하고 있다는 것입니다. 그리고 인덱스가 1인 경우에는 vector을 통해서 간접적으로 access하지 않고, 해당 포인터를 통해서 access하고 있었습니다. 이렇게 관리하는 이유는 성능상의 이유가 가장 큰고, Observable의 사이즈가1인 경우가 대부분이기 때문에 이렇게 구현한것 같습니다. 그리고 StartObserver와 StopObserver을해당 객체를 컨트롤하고 있습니다.
Blob
Blob은 형식화된 pointer를 호스팅하는 일반 컨테이너입니다.
Blob은 pointer와 해당 유형을 호스팅하며, Blob이 할당 해제되거나 새 유형으로 재할당될 때 적절하게 삭제하는 일을 담당합니다. (Blob은 무엇이든 포함할 수 있지만, 일반적인 경우 Tensor를 포합니다.)
Blob class는 pointer를 void* 형태로 객체를 관리하다가, template Get***()함수들을 통해 해당 타입으로 객체를 리턴합니다.
참고로 Blob은 intrusive_ptr을 사용하기 위해서 c10::intrusive_ptr_target을 상속 받아 구현되어 있고, intrusive_ptr는 더 좋은 성능으로 std::shared_ptr를 대체합니다.
또한 해당 pointer에 대한 정보를 meta_(TypeMeta)로 관리합니다. TypeMeta은 데이터 유형을 고유한 런타임 ID와 함께 저장할 수 있는 클래스이며, 런타임 검사를 위한 항목 크기 및 유형 이름과 같은 일부 추가 데이터를 저장합니다.
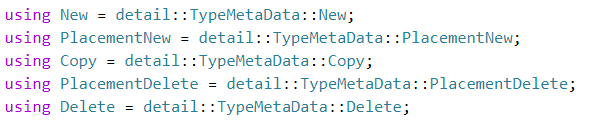
위와 같은 유형으로 blob을 관리하는 이유는 Memory Pool을 사용하기 때문으로, Memory Pool에서 가져온 버퍼들은 함부로 삭제해서는 안되기 때문입니다.
NetBase (Network)
Network는 operator의 집합체 입니다. 그리고 이러한 operator을 어떻게 동작하느냐에 따라서 SimpleNet, ParallelNet으로 구분됩니다.
(추가적으로 AsyncNetBase가 존재하고, 주석을 통해서 GPU계산시 실험적으로 muti stream을 지원한다고 되어 있다고 명시되어 있지만 코드를 확인하지 못했습니다.)
- SimpleNet: sequential하게 operator들을 생성하고 동작시키게 됩니다.
- ParallelNet: CPU와 GPU에 대해서 Device Pool(TaskThreadPoolBase)을 가지고 있고, AsyncTaskGraph를 생성하고 이를 통해서 병렬적으로 동작합니다.
Workspace
Workspace는 런타임 중에 생성된 모든 관련 객체(Blob, Network)들을 보유하는 클래스입니다.
(여기서, Blob은 형식화된 포인터를 호스팅하는 일반 컨테이너이고, )
- NetDef를 통해서 Network(NetBase)를 생성합니다.
- unordered_map을 통해 생성한 Network들을 관리합니다.
- 관리되는 Network를 실행시킵니다.
- NetBase관련 정보들을 출력합니다.
Operator
operator은 실제 계산이 이루어지는 연산자를 의미합니다. 그리고 이 연산자는 아래의 그림과 같이 OperatorBase를 상속받고, 우리는 Operator를 상속받아서 RunOnDevice()를 구현하게 되면 Custom한 연산자를 구현할 수 있습니다.

Input과 Output을 좀 더 직관적으로 관리할 수 있게 아래와 같은 매크로도 지원합니다.

operator의 생성자에서는 operator_def(OperatorDef)를 기반으로 input과 output (blob)을 생성합니다.
이때 blob 객체를 생성 하는거지 내부에 메모리 할당까지 이루어지지는 않습니다. 그리고 이 blob들의 ownership은 Workspace에서 가지고 있습니다. 또한 Blob은 단순히 그 자체로 사용되지 않고, shape, device 정보등등 다양한 메타정보를 포함하는 Tensor로 변환되어 상속받은 operator에서 사용되게 됩니다.
OperatorBase::OperatorBase(const OperatorDef& operator_def, Workspace* ws)
: operator_ws_(ws),
operator_def_(std::make_shared<OperatorDef>(operator_def)),
device_option_(
operator_def.has_device_option() ? operator_def.device_option()
: DeviceOption()),
input_size_(operator_def.input_size()),
event_(std::make_unique<Event>(device_option_)) {
static GlobalInitIsCalledGuard guard;
inputs_.reserve(operator_def.input_size());
for (const string& input_str : operator_def.input()) {
inputs_.push_back(ws->GetBlob(input_str));
}
// ...
outputs_.reserve(operator_def.output_size());
for (const string& output_str : operator_def.output()) {
outputs_.push_back(ws->CreateBlob(output_str));
}
type_ = operator_def.type();
}Operator를 상속 받은 하위 클래스들은 아래 처럼 Input과 Output 함수를 통해서 원하는 타입과 Shape의 Tensor 데이터를 가져올 수 있습니다.

아래의 링크를 통해서 Operator 하위에 어떤 Class들이 구현되어 있는지 확인할 수 있습니다.
Caffe2 - C++ API: caffe2::Operator< Context > Class Template Reference
Caffe2 - C++ API: caffe2::Operator< Context > Class Template Reference
template class caffe2::Operator< Context > Definition at line 677 of file operator.h.
caffe2.ai
정리
caffe2에서 다양한 타입과 형태의 데이터를 입력으로 받거나 출력으로 내보낼 수 있었던 이유는 연산을 수행하는 곳에서 직접 관리하지 않고 역활을 잘 쪼개놓았기 때문입니다. 즉 Blob은 데이터의 Lifecycle만 관리하고, Tensor는 해당 데이터를 가공하는 역활 그리고 Operator은 이러한 데이터를 가져와 사용하는 역활만 수행하고 있습니다.
구체적인 예시는 아래로 들 수 있습니다.


또한 위처럼 perfect forwarding을 통해서 operator에서 필요한 다양한 값들을 넘기고 OP_SINGLE_ARG 매크로 함수를 통해서 해당 값들을 가져오고 있습니다. 두 번째 이미지는 가변길이 템플릿을 통해서 값들을 넘기는 모습을 간단하게 나타낸 코드입니다. (저 매크로 함수의 내부에서는 FunctionSchema라는 Class를 통해서 값들을 가져옵니다.)
'C++' 카테고리의 다른 글
| [CppCon] 분산 데이터 구조와 Parallel Programming (1) | 2023.12.24 |
|---|---|
| [빌드] WSL2에서 Triton 빌드 실패 시 (0) | 2023.08.29 |
| [오픈 소스] Facebook(Meta)의 오픈소스 라이브러리 Folly (0) | 2023.07.12 |
| [기본] 소멸자의 virtual 키워드에 대해 (0) | 2023.06.25 |
| [CppCon] C++에서 데이터를 Handling하기 위한 다양한 구조들 (0) | 2023.04.20 |



