[실습] CUDA MergeSort 구현 (Naive 버전) (tistory.com)
[실습] CUDA MergeSort 구현 (Naive 버전)
CUDA에서 정렬을 구현한다고 할때, 가장 먼저 드는 생각은 우리가 알고 있는 알고리즘들(Quick Sort, Merge Sort, Buble Sort 등등.. )을 병렬로 바꿔볼까 하는생각들을 하게 될것 입니다. 그러면 이게 생각
hotstone.tistory.com
이전 시간에 기존에 CPU에서 동작하는 방식을 그대로 CUDA에서 Merge Sort를 구현했었습니다. 그런데 당연하게도 std::qsort에 비해 한참 떨어지는 성능을 보여줬었고, 따라서 CUDA에서는 정렬을 구현한다면 어떻게 해야 하는지 Nvidia의 예제를 참고하게 되었습니다. 오늘은 제가 분석한 Nvidia MergeSort에 대해서 이야기 해보겠습니다.
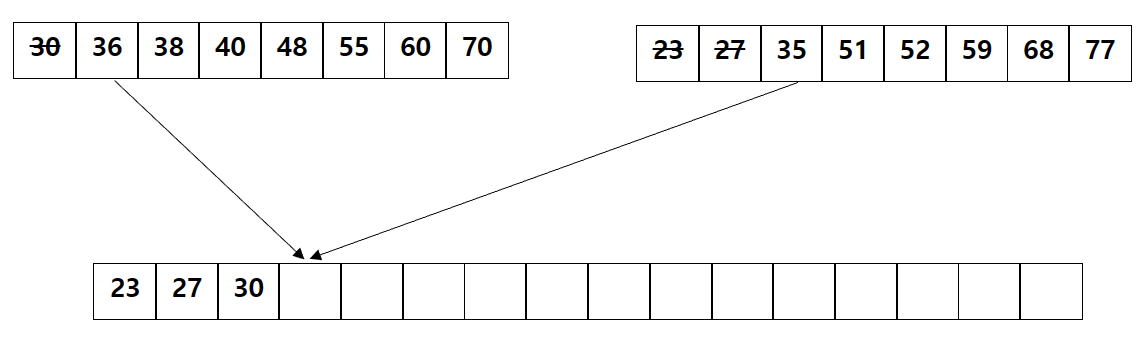
이전에 Naive한 버전의 Merge Sort를 구현하는 과정에 가장 성능이 안나오는 부분은 위의 이미지 처럼 두 개의 정렬된 sub 배열을 받아서 merge 하는 부분이었습니다. 왜냐하면 정렬된 두 배열에서 값을 하나씩 빼와 값을 비교후 정렬해야 했기에 stride가 증가할 수록 merge에 참여하지 않는 thread의 개수가 2의 지수함수로 증가하게 되어 좋은 성능을 낼 수 없는 구조였습니다. 그리고 우리가 이렇게 값을 비교해야만 하는 이유는 정렬된 두 배열의 값들이 합쳐질 배열에서 어느 위치에 놓일지 알 수 없기 때문에 수행하는 것이었습니다. 그렇다면 정렬된 두 배열의 각각의 값들이 합쳐질 배열에 어느 곳에 위치해야 하는지 알 수 있다면 이를 병렬로 처리할 수 있다는 뜻이됩니다.
그리고 이걸 그림으로 표현하면 아래와 같이 될 수 있을 것 입니다.
(위의 배열은 인덱스를 나타냅니다.)
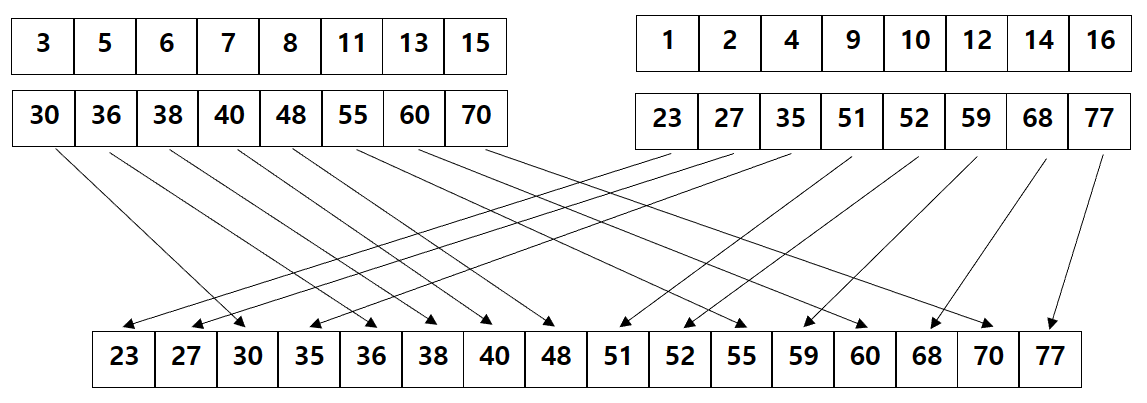
위 이미지를 보게 되면 각각의 원소가 합쳐질 배열의 인덱스를 가지고 있고 그 값을 바탕으로 정렬된 배열을 구성하고 있습니다. 그리고 아래의 코드가 global memory의 인덱스를 조정하고, shared memory를 선언 및 초기화 하는 부분입니다.
참고로 이때 d_SrcKey에는 정렬될 값들이 들어 있고, d_SrcVal에는 인덱스 값이 들어 있습니다.
위 이미지로 예로 들면 위 배열이 d_SrcVal라고 할 수 있고, 아래 배열이 d_SrcKey라고 할 수 있습니다.
__global__ void mergeSortSharedKernel(uint *d_DstKey, uint *d_DstVal,
uint *d_SrcKey, uint *d_SrcVal,
uint arrayLength) {
__shared__ uint s_key[SHARED_SIZE_LIMIT]; // 1024, thread 개수 = 512
__shared__ uint s_val[SHARED_SIZE_LIMIT];
// global memory의 인덱스를 편하게 다루기 위해서 현재 인덱스 기준으로 바꿉니다.
d_SrcKey += blockIdx.x * SHARED_SIZE_LIMIT + threadIdx.x;
d_SrcVal += blockIdx.x * SHARED_SIZE_LIMIT + threadIdx.x;
d_DstKey += blockIdx.x * SHARED_SIZE_LIMIT + threadIdx.x;
d_DstVal += blockIdx.x * SHARED_SIZE_LIMIT + threadIdx.x;
// shared memory를 초기화 합니다.
s_key[threadIdx.x + 0] = d_SrcKey[0];
s_val[threadIdx.x + 0] = d_SrcVal[0];
s_key[threadIdx.x + (SHARED_SIZE_LIMIT / 2)] =
d_SrcKey[(SHARED_SIZE_LIMIT / 2)];
s_val[threadIdx.x + (SHARED_SIZE_LIMIT / 2)] =
d_SrcVal[(SHARED_SIZE_LIMIT / 2)];
...
}shared memory의 초기화가 마무리 되면, 이제 부터 stride를 증가해 가면서 sub 배열들을 정렬해 나갑니다.
그런데 이때 이전에 이야기 했듯이 합쳐질 배열의 인덱스를 구해야 합니다. 그리고 두 배열은 정렬된 상태이기 때문에 성능을 위해 binary search 를 사용하여 다른 각각 다른 배열에서의 해당값의 position값을 구합니다.
그리고 현재 배열에서의 position값(lPos)를 더하게 되면 최종적인 정렬된 배열의 postion값을 구할 수 있습니다. 마지막으로 최종 position값을 받아서 해당 위치에 key와 value를 갱신합니다.
// stride 값을 2배씩 증가해 가며, 인덱스를 갱신합니다.
for (uint stride = 1; stride < arrayLength; stride <<= 1) {
// 기준이 되는 인덱스 계산합니다.
// e.g: stride가 4일 경우 threadIdx.x에 따라서 lPos는 0, 1, 2, 3, 0, 1, 2, 3, ... 으로 구성됩니다.
// 따라서 threadIdx.x - lPos를 함으로써 stride별 기준이 되는 인덱스를 구할 수 있습니다.
// e.g: 0, 0, 0, 0, 8, 8, 8, 8, 16, 16, ...
uint lPos = threadIdx.x & (stride - 1);
uint *baseKey = s_key + 2 * (threadIdx.x - lPos);
uint *baseVal = s_val + 2 * (threadIdx.x - lPos);
cg::sync(cta);
// 현재의 key와 value를 저장합니다.
uint keyA = baseKey[lPos + 0];
uint valA = baseVal[lPos + 0];
uint keyB = baseKey[lPos + stride];
uint valB = baseVal[lPos + stride];
// binary Search를 활용하여 값(key)에 대한 인덱스를 구합니다.
// posA = sub배열B에서의 인덱스 + A에서의 인덱스(lPos)
uint posA =
binarySearchExclusive<sortDir>(keyA, baseKey + stride, stride, stride) +
lPos;
uint posB =
binarySearchInclusive<sortDir>(keyB, baseKey + 0, stride, stride) +
lPos;
cg::sync(cta);
baseKey[posA] = keyA;
baseVal[posA] = valA;
baseKey[posB] = keyB;
baseVal[posB] = valB;
}그런데 이때 주의해야할 상황이 존재합니다. 바로 두 sub 배열에 같은 값이 존재할 때 입니다. 이런 경우에 position을 찾는 함수를 사용할 때 같은 함수를 사용하게 된다면 아래 처럼 같은 position값을 인덱스로 가지게 됩니다.
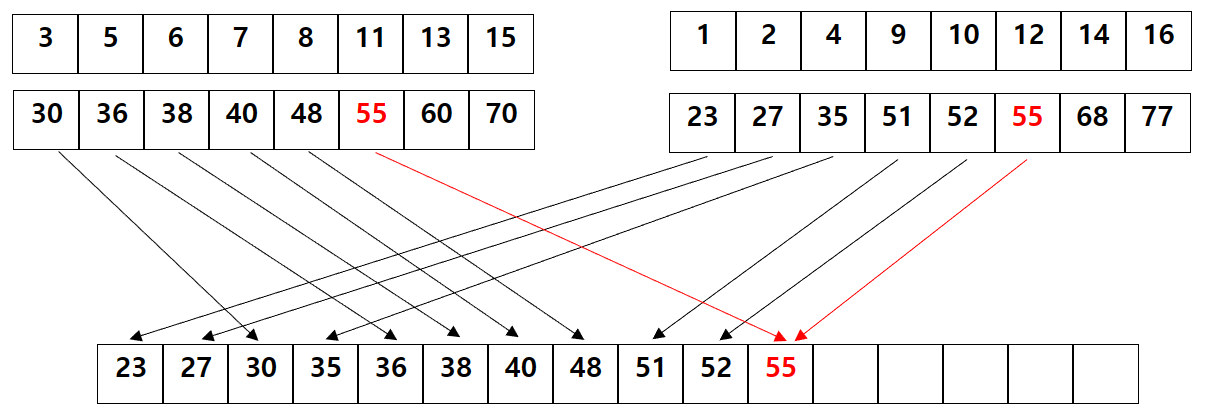
따라서 각각의 sub 배열에서 position값을 구할 때는 하나에서는 해당 값을 포함한 position을 구하고, 다른 sub 배열에서는 해당 값을 포함하지 않는 position을 구하게 함으로써 인덱스가 겹치는 경우를 방지할 수 있습니다.
template <uint sortDir>
static inline __device__ uint binarySearchInclusive(uint val, uint *data,
uint L, uint stride) {
if (L == 0) {
return 0;
}
uint pos = 0;
for (; stride > 0; stride >>= 1) {
uint newPos = umin(pos + stride, L);
// 이 함수는 val를 포함한 position값을 리턴합니다.
if ((sortDir && (data[newPos - 1] <= val)) ||
(!sortDir && (data[newPos - 1] >= val))) {
pos = newPos;
}
}
return pos;
}
template <uint sortDir>
static inline __device__ uint binarySearchExclusive(uint val, uint *data,
uint L, uint stride) {
if (L == 0) {
return 0;
}
uint pos = 0;
for (; stride > 0; stride >>= 1) {
uint newPos = umin(pos + stride, L);
// 이 함수는 val를 제외한 position값을 리턴합니다.
if ((sortDir && (data[newPos - 1] < val)) ||
(!sortDir && (data[newPos - 1] > val))) {
pos = newPos;
}
}
return pos;
}
마지막으로 아래 코드처럼 shared memory에 정렬된 값들을 global memory에 옮겨옴으로써 해당 커널 함수의 동작은 마무리 됩니다.
cg::sync(cta);
d_DstKey[0] = s_key[threadIdx.x + 0];
d_DstVal[0] = s_val[threadIdx.x + 0];
d_DstKey[(SHARED_SIZE_LIMIT / 2)] =
s_key[threadIdx.x + (SHARED_SIZE_LIMIT / 2)];
d_DstVal[(SHARED_SIZE_LIMIT / 2)] =
s_val[threadIdx.x + (SHARED_SIZE_LIMIT / 2)];하지만 아직 정렬이 마무리된게 아닙니다.
지금까지는 Shared Memory를 이용하여 Block Size(512) x 2 = 1024 개를 정렬를 수행한 것이고, 완전한 정렬를 하기 위해서는 Global Memory 단계에서 정렬이 수행되어야 합니다.
따라서 다음 글에서는 배열 전체를 갱신시키는 과정에 대해서 이야기 해보겠습니다.
전체적인 source code는 아래의 링크에서 확인해 보실 수 있습니다.
cuda-samples/mergeSort.cu at v11.6 · NVIDIA/cuda-samples (github.com)
GitHub - NVIDIA/cuda-samples: Samples for CUDA Developers which demonstrates features in CUDA Toolkit
Samples for CUDA Developers which demonstrates features in CUDA Toolkit - GitHub - NVIDIA/cuda-samples: Samples for CUDA Developers which demonstrates features in CUDA Toolkit
github.com
'병렬 프로그래밍 > CUDA' 카테고리의 다른 글
| [기본] Visual Studio에서 CUDA 디버깅 하기 (0) | 2023.04.11 |
|---|---|
| [실습] Nvidia의 MergeSort 예제 분석 - 2 (0) | 2023.04.02 |
| [실습] CUDA MergeSort 구현 (Naive 버전) (0) | 2023.03.21 |
| [빌드] CUDA에서 Separate Compilation과 Linking 이슈 (0) | 2023.03.07 |
| [실습] CUDA의 Cooperative Groups (0) | 2023.03.05 |



